

Blog
Betrouwbare AI-oplossingen binnen
B2B commerce
In B2B draait het niet om een antwoord, maar om een antwoord dat je kunt controleren. Leer meer over het gebruik van guardrails, data-eisen en de rol van PIM.
Scroll down for positive impact
Datum
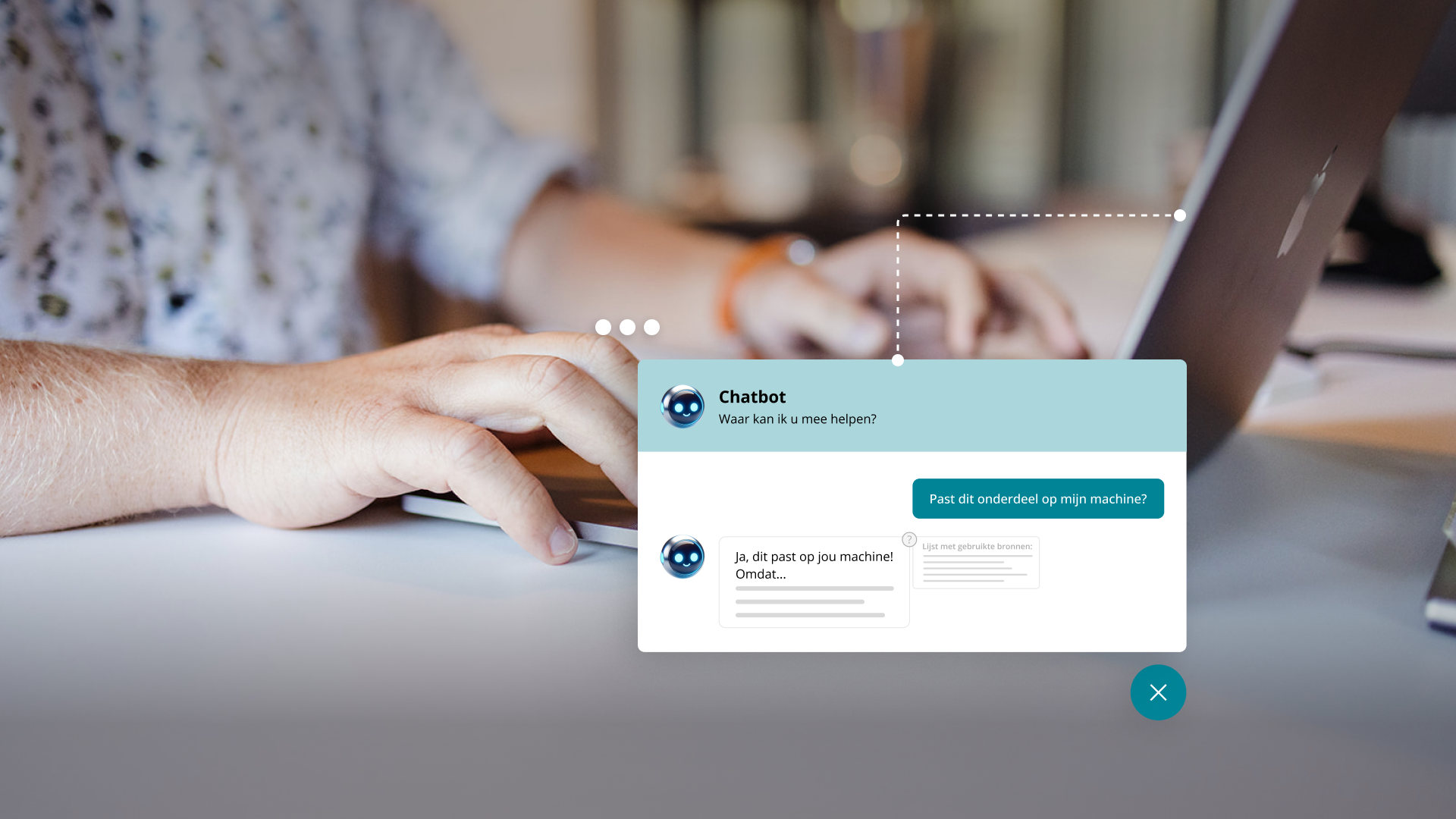
"Onze AI-assistent praat vlot... maar durven klanten hem te vertrouwen?"
Is AI de snelle route naar betere self-service bij een B2B organisatie? Een chatbot die vragen beantwoordt, een agent die de juiste producten adviseert of AI-gestuurde search die “snapt wat de klant bedoelt”. Maar zodra de AI een plausibel antwoord geeft dat net niet klopt, is het vertrouwen weg en daarmee ook de adoptie. In B2B zijn de foutkosten simpelweg hoger want verkeerde specificaties, compatibiliteit of beschikbaarheid raken direct processen, orders en klantrelaties.
En tegelijk is de realiteit hard. AI-projecten stranden vaak niet op het model, maar op de data erachter. Gartner voorspelt dat organisaties tot en met 2026 60% van AI-projecten zullen verlaten als ze niet worden ondersteund door AI‑ready data.
Wat betekent vertrouwen in B2B met AI?
In B2B gaat vertrouwen niet over “menselijk klinken”. Het gaat over drie dingen:
- Juistheid: klopt het antwoord met de productrealiteit (specificaties, varianten, compatibiliteit)?
- Controleerbaarheid: kun je herleiden waarom dit antwoord is gegeven en welke brondata is gebruikt?
- Consistentie binnen business rules: past het antwoord binnen contractafspraken, assortimentsrechten en beschikbaarheid (wat mag deze klant zien/kopen, en tegen welke voorwaarden)?
Vertrouwen in B2B ontstaat door een gestructureerd koopproces, traceerbaarheid en aansluiting op de business rules, niet door “mooie” output.
Transparantie is de standaard
Van “AI antwoordt” naar “AI onderbouwt”
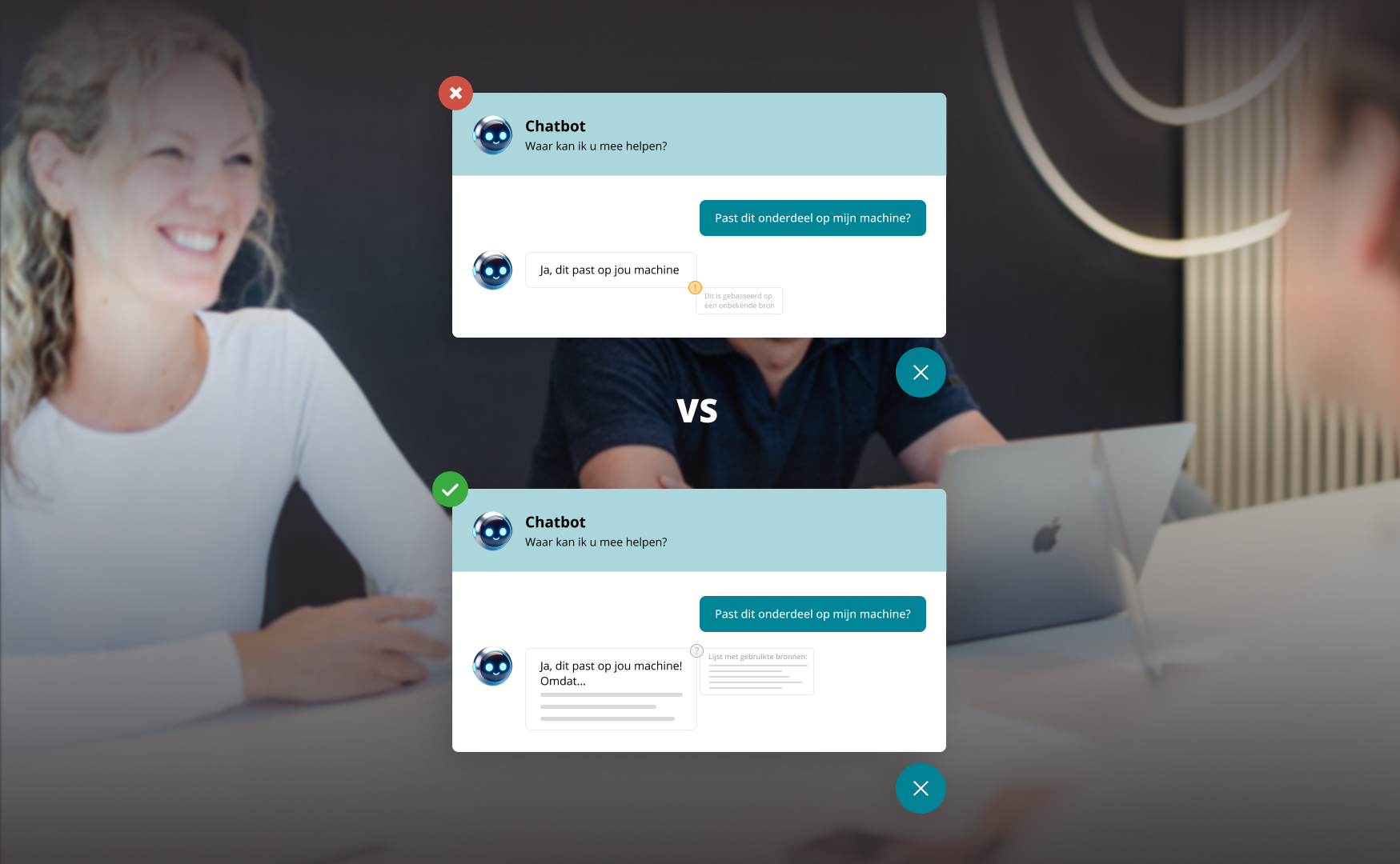
Het geven van inzicht hoe AI tot een antwoord komt en waar het vandaan komt is essentieel. In commerce is dat praktisch een bronverwijzing naar productdata, regels die het antwoord begrenzen en logica die je kunt auditen.
Dat is niet alleen compliance. Het is ook een voorwaarde voor adoptie. Organisaties die werken met AI hebben regelmatig te maken met onnauwkeurige of misleidende output. Daarnaast zien we dat er veel zorgen zijn over o.a. security/privacy en compliance bij AI-output in de praktijk.
Daarnaast komt governance naar voren als ontwerp-eis. De EU AI Act introduceert transparantie-verplichtingen voor bepaalde AI-systemen (bijvoorbeeld wanneer mensen met AI interacteren) en zet vanuit bestuur structuren neer voor toezicht. Dat maakt uitlegbaarheid en controle steeds normaler als verwachting.
Omgang met AI moet strict zijn
B2B-commerce heeft extra lagen die AI móét respecteren, anders voelt het direct als onbetrouwbaar aan. Denk maar eens aan:
- Contractpricing & klantafspraken: het juiste product tegen de juiste prijs voor de klant.
- Assortimentsrrechten: klant A mag product X wél zien, klant B niet.
- Beschikbaarheid & levercondities: wat is leverbaar, waar, wanneer en onder werlke voorwaarden?
- Compabiliteit & veiligheid: een onjuist attribuut of verkeerde variant kan downstream processen verstoren.
Een mogelijk herkenbaar scenario is dat een AI-assistent een “bijpassend” onderdeel adviseert, maar negeert een compatibiliteitsregel of een variant-attribuut. De klant bestelt en ontdekt later dat het niet past. Hierdoor neemt het vertrouwen in AI af maar nog belangrijker, in de organisatie.
AI vergroot de zichtbaarheid van dataproblemen maar lost ze niet automatisch op.
Veel voorkomende oorzaken van onbetrouwbare output van AI in Commerce
Hier gaat het in de praktijk nog wel eens mis:
- Onvolledige of ongestructureerde productdata. Belangrijke specificaties zitten in vrije tekst of PDF’s.
- Meerdere “sources of truth” (ERP/PLM/PIM/spreadsheets) met tegenstrijdige waarden.
- Geen duidelijke ownership. Niemand is verantwoordelijk voor end-to-end productdata kwaliteit.
- Governance alleen op papier. Validatieregels en workflows bestaan, maar worden niet consequent toegepast.
- AI zonder contextregels: de AI mag antwoorden buiten contracten, assortiment of beschikbaarheid en dat voelt meteen “fout”.
Organisaties onderschatten nog wel eens het verschil tussen traditionele datamanagement en AI-ready data, en zonder die basis lopen AI-initiatieven vast.
De rol van PIM en integraties
Het hebben of genereren van veel data is niet het doel op zich. Maar zorgen dat data bruikbaar is voor AI én voor auditing wel. Denk daarbij aan:
- Gestructureerde attributen (niet verborgen in tekst).
- Relaties/varianten expliciet gemodelleerd (compatibiliteit, bundels, substituten).
- Metadata & traceability: je weet waar waarden vandaan komen en wanneer ze zijn gewijzigd.
- Governance-workflows: review, goedkeuring en audit trail zijn ingericht. Zeker bij kritieke attributen.
Een PIM is de plek waar je dit borgt doordat het een gecentraliseerd en gecontroleerde bron voor producten is. AI gebruikt die bron in discovery, personalisatie en agentic commerce wat het betrouwbaar maakt.

Voorbeeld van guardrails voor klantgerichte AI
Als je AI klantgericht inzet, behandel het dan als een assistent die binnen bepaalde regels werkt, niet als een losstaande chatbot. Dit zijn praktische guardrails:
- Bronvermelding per antwoord: toon welke productdata/bron de basis is.
- Werk binnen klantcontext: contractprijzen, assortimentsrechten en beschikbaarheid als harde grenzen.
- Human-in-the-loop bij kritieke informatie: laat AI een voorstel doen waarna de mens het goed keurt (of AI escaleert automatisch).
- Confidence + “ik weet het niet”: als data ontbreekt of te onzeker is, moet de AI dat expliciet zeggen en doorverwijzen.
- Logging & audit trail: log prompts, bronnen, versie van productdata en output zodat je kunt analyseren en verbeteren.
- Validatieregels in de datalaag: zorg dat kritieke attributen (veiligheid/compatibiliteit) niet “vrij” kunnen worden gegenereerd zonder controle.
- Rollen en rechten: geef interne teams meer “diepte” dan externe buyers (niet alles is publiek)
Waar begin je?
De meeste verbeteringen beginnen niet met technologie, maar met inzicht:
- Waar komt je productinformatie vandaan?
- Waar ontstaan verschillen?
- Welke data is leidend en welke niet?
Van daaruit start je waar impact meetbaar is en het risico beheersbaar blijft. Denk aan AI voor interne support. Zoals het versnellen van product content, het verbeteren van search synoniemen of het voorbereiden van antwoorden mét bronverwijzing die een medewerker accordeert.
Kies één categorie of productlijn en maak die “AI-ready” met duidelijke attribuut-standaarden, ownership en reviewflows. AI-ready data is een iteratief proces met o.a. metadata en governance die je moet laten groeien per use-case.
Als je dit stapsgewijs doet, bouw je vertrouwen op bij stakeholders én voorkom je dat AI het probleem zichtbaar maakt en dat je het beheersbaar houdt.

Download onze whitepaper
Wil je AI in B2B commerce inzetten zonder het vertrouwen van je kopers te verliezen?
Ontdek welke productdata- en governance fundamenten je nodig hebt voor betrouwbare AI in search, personalisatie en assistentie.

Door Tom Heinen
Business development



Let's create positive
impact together!
Onze informatie
Brouwerijstraat 1-A1
7523 XC Enschede
Certificeringen


